Simple chaining (sometimes referred to as Separate chaining), is a collision resolution strategy followed in the concept of Hashing. As per the simple chaining strategy whenever there is a collision in HashTable, instead of looking for any other slot we prefer putting the data in the initial bucket i.e.i.e. generated by the hash function. So we would require some sort of data structure to contain all the data for each of the buckets.
Takeaways
Each node of a Doubly linked list contains the memory address of the previous and next node.
In Simple Chaining, What Data Structure is Appropriate?
- Singly Linked List
- Doubly Linked List
- Red Black Trees
- Segment Trees
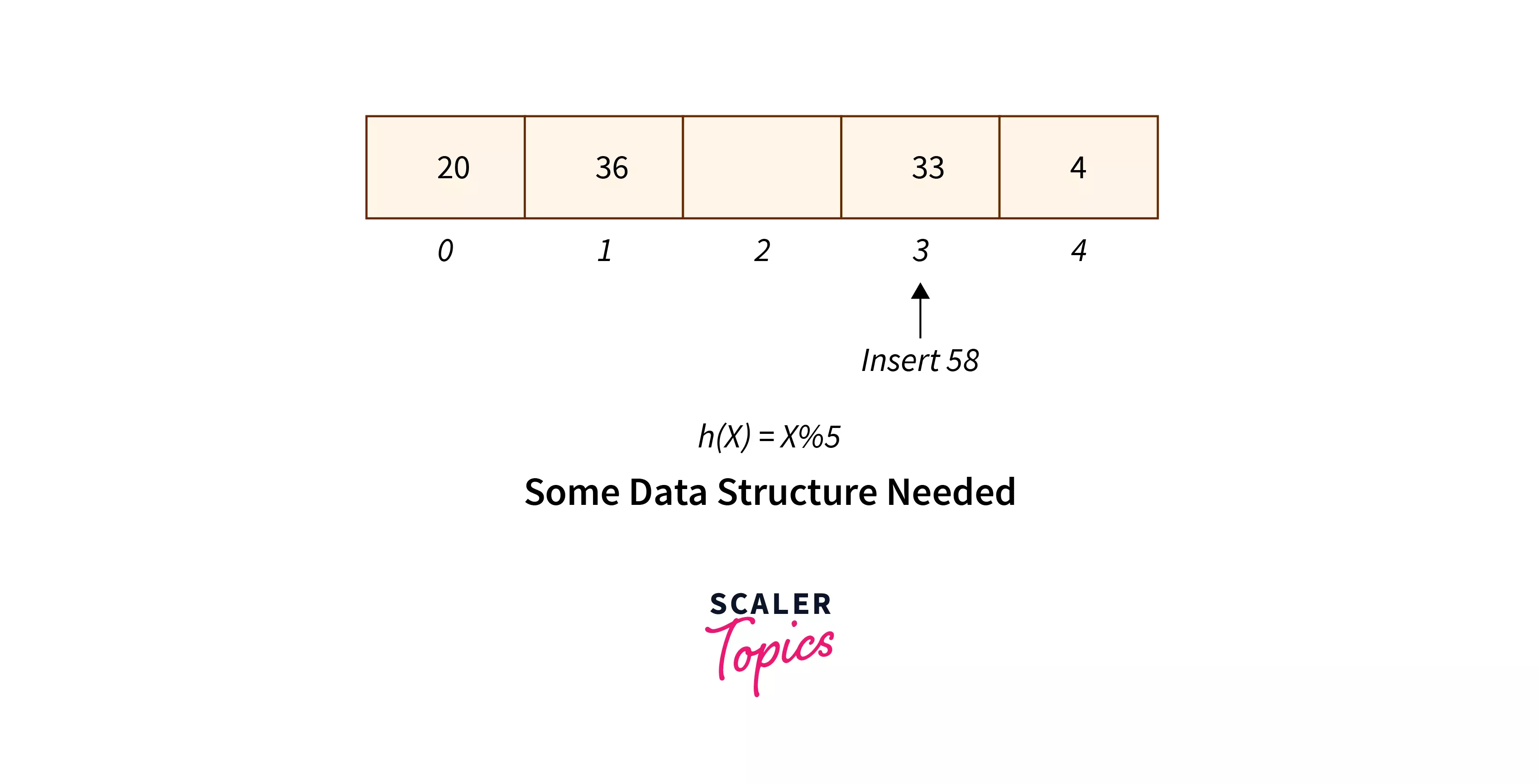
Answer – Doubly Linked List is an appropriate data structure for simple chaining.
What is a Doubly Linked List?
Doubly Linked Lists are nothing but a slight variation of singly linked lists. As the name suggests, in doubly linked lists we can traverse in both directions i.e.i.e. forward and backward unlike singly linked lists where we can only traverse in the forward direction.
Doubly Linked List is most widely used to implement undo and redo functionality in different application software like MS Word, Google docs, Premiere Pro, File Explorer, etc. Similarly, it can also be used to traverse back and forth in the chain/list of data in a Hash Table.
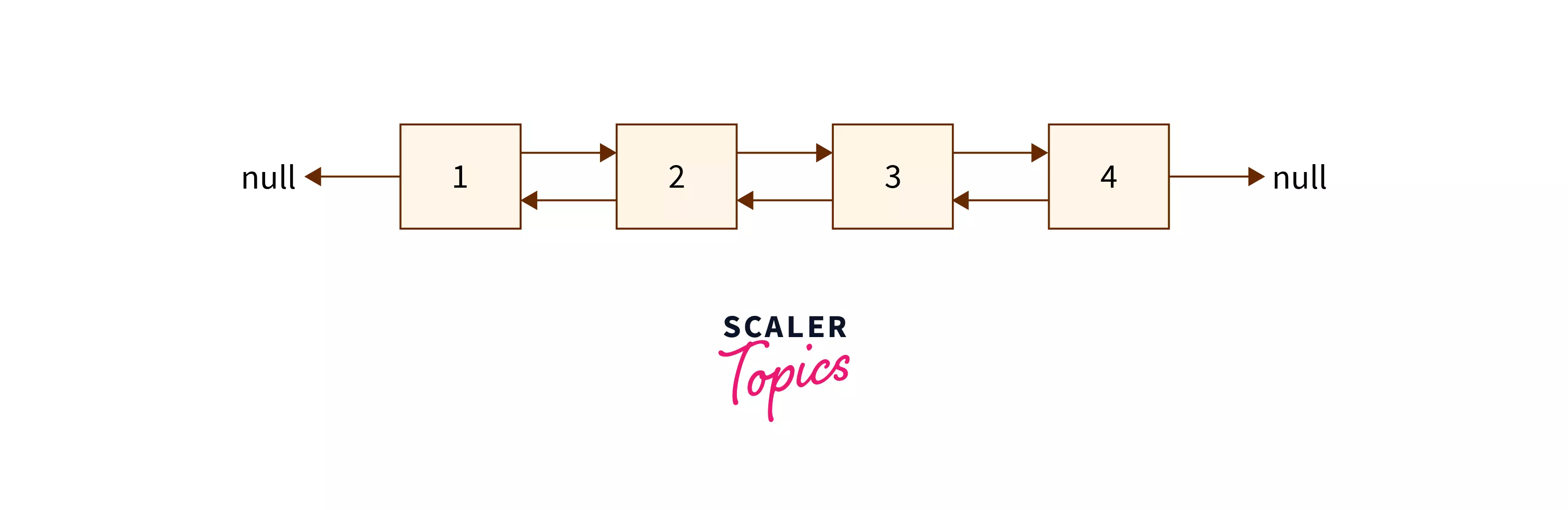
Representation of Doubly Linked List
In each node of the doubly linked list, we have the following data –
- Value of the node.
- Address of the backward node (null in the case of the head node).
- Address of the forward node (null in the case of the tail node).
And in coding terms, it is represented in the following way –
class Node{
// Value of the node.
int data;
// Address of the next node.
Node next;
// Address of the previous node.
Node prev;
}
Operations in Doubly Linked List
All the operation in the Doubly linked list and their time complexities is almost the same as in the singly linked list.
| Insertion | Accessing | Deletion | |
|---|---|---|---|
| Head Node | O(1) | O(1) | O(1) |
| Tail Node | O(n) | O(n) | O(n) |
| kth Node | O(k) | O(k) | O(k) |
As it can be seen, all the operation in the Doubly linked list cost O(n) time in the worst case and also in the average case, while all of them requires constant time in the best case.
The time complexity of operations at the tail node can be brought down to O(1) by storing the address of the tail node at every instance of time in a Node type variable (say tail), so that you can directly access/remove the tail node. And when inserting after the tail node, use the same variable to insert and then update it.
We have seen that we can perform all the operations efficiently in the doubly linked list hence the doubly linked list is an appropriate data structure to use in simple chaining.
Learn More
We strongly suggest you read the detailed article on Doubly Linked List to know how we can perform various operations in the doubly linked lists, how we can implement linked list using different ways, etc.
Conclusion
- Doubly linked list consumes more memory because each node has one additional node.
- Doubly linked list is possible to traverse in both forward in backward direction.
- Browsers like Google Chrome have “Go Forward” and “Go backward” buttons (see top left corner), to transverse back to the visited websites, which are represented using the doubly Linked list.
- All Operating systems offer functionality to switch the applications using the alt + Tab and shift + alt + Tab key combination which is also a use case of Doubly Linked List.